Technologie
Kafka 101 Tutorial - Erste Schritte mit Confluent Kafka

29. März 2023

Wir zeigen, wie man einen lokalen Kafka-Cluster mit Docker Containern betreibt. Wir werden auch zeigen, wie man mit Hilfe der CLI Ereignisse aus Kafka produziert und konsumiert.
Die Infrastruktur
Der Cluster wird mit Confluent-Images eingerichtet. Insbesondere werden wir 4 Dienste einrichten:
- Zookeeper
- Kafka Server (der Broker)
- Confluent Schema Registry (zur Verwendung in einem späteren Artikel…)
- Confluent Control Center (die Benutzeroberfläche zur Interaktion mit dem Cluster)
Beachten Sie, dass mit Kafka 3.4 die Möglichkeit eingeführt wird, einen Kafka-Cluster vom Zookeeper- in den KRaft-Modus zu verschieben. Zum Zeitpunkt der Erstellung dieses Artikels hat Confluent das neue Docker-Image mit Kafka 3.4 noch nicht veröffentlicht. Daher verwenden wir in diesem Tutorial weiterhin Zookeeper. Eine Diskussion über Zookeeper und KRaft finden Sie in diesem Artikel.
Die Dienste werden mithilfe von docker-compose hochgefahren und orchestriert. Lassen Sie uns kurz die Konfigurationen durchgehen.
Zookeeper
Wie üblich müssen wir Zookeeper mit unserem Kafka-Cluster verbinden. Zookeeper ist für die Speicherung von Metadaten über den Cluster zuständig (z. B. wo sich die Partitionen befinden, welche Replik die führende ist, usw.). Dieser “zusätzliche” Dienst, der immer zusammen mit einem Kafka-Cluster gestartet werden muss, wird bald veraltet sein, da die Verwaltung der Metadaten vollständig in den Kafka-Cluster integriert wird, indem der neue Kafka-Raft-Metadatenmodus, abgekürzt KRaft, verwendet wird.
Die Confluent-Implementierung von Zookeeper bietet ein paar Konfigurationen, die hier verfügbar sind.
Insbesondere müssen wir Zookeper mitteilen, auf welchem Port es auf Verbindungen von Clients, in unserem Fall Apache Kafka, hören soll. Dies wird mit dem Schlüssel ZOOKEEPER_CLIENT_PORT konfiguriert. Sobald dieser Port ausgewählt ist, muss der entsprechende Port im Container freigegeben werden. Diese Konfiguration allein reicht aus, um die Kommunikation zwischen dem Kafka-Cluster und Zookeeper zu ermöglichen. Die entsprechende Konfiguration ist unten verfügbar, wie sie in unserer docker-compose Datei verwendet wird.
| |
Kafka Server
Wir müssen auch einen einzelnen Kafka-Broker konfigurieren, mit einer minimalen, praktikablen Konfiguration. Wir müssen die Port-Zuordnungen und die Netzwerkeinstellungen (Zookeeper, angekündigte Listener usw.) festlegen. Außerdem legen wir einige grundlegende Konfigurationen für Logging und Metriken fest.
Details zur Konfiguration finden Sie auf der Confluent-Website; und alle Konfigurationen können hier gefunden werden.
| |
Start des Clusters
Um den Cluster zu starten, klonen Sie zunächst das Repository; und wechseln lokal mit cd in das Repository.
Stellen Sie sicher, dass die Ports, die von localhost gemappt werden, nicht bereits verwendet werden und dass Sie keine laufenden Container mit denselben Namen wie die in unserer Datei docker-compose.yaml definierten haben (überprüfen Sie den Konfigurationsschlüssel
container_name).
| |
Um den Cluster zu starten, führen Sie einfach diesen Befehl aus
| |
Abhängig von der Docker-Version, die Sie haben, könnte der Befehl folgendermassen lauten
| |
Um zu überprüfen, ob alle Dienste gestartet sind, führen Sie den folgenden Befehl aus
| |
Die Ausgabe sollte sein
| |
Sie sollten nun in der Lage sein, auf den Container control-center zuzugreifen, der die Confluent-Benutzeroberfläche für die Verwaltung von Kafka-Clustern auf localhost:9021 darstellt. In den Online-Ressourcen finden Sie eine Führung durch Confluent control center.
Produzieren und Konsumieren von Messages mit der CLI
Bei Kafka gibt es die Begriffe Producer und Consumers. Producers sind Client-Anwendungen, die Daten in den Cluster schreiben. Consumers hingegen lesen Daten aus dem Cluster und führen letztendlich Arbeit auf den gelesenen Daten aus, wie beispielsweise eine Flink-Anwendung. Confluent bietet CLI-Tools, um Messages über die Befehlszeile zu erzeugen und zu konsumieren. In diesem Abschnitt werden wir uns das Folgende ansehen:
- Erstellen eines Topics
- Schreiben (Produzieren) in das Topic
- Lesen (konsumieren) aus dem Topic
Um auf die CLI-Tools zuzugreifen, müssen wir in den broker-Container gehen.
| |
Ein Topic erstellen
In diesem Beispiel erstellen wir ein einfaches Topic im Cluster mit den Standardkonfigurationen. Wir erstellen ein Topic mit dem Namen my-amazing-topic mit einem Replikationsfaktor von 1 und einer Partitionierung von 1. Das bedeutet, dass Messages nicht repliziert werden (1 Message wird nur auf einem Server gespeichert) und nicht partitioniert werden (1 Partition ist gleichbedeutend mit keiner Partitionierung). Das bedeutet, dass das Topic in 1 Log aufgeteilt wird.
Um dieses Topic zu instanziieren, führen Sie den folgenden Befehl innerhalb des Containers broker aus
| |
Wenn der Befehl erfolgreich ist, wird er Folgendes ausgeben
| |
Sie können auch überprüfen, ob das Topic erfolgreich erstellt wurde, indem Sie zur Registerkarte Topics der Web-Benutzeroberfläche navigieren; dort sollte das neu erstellte Topic mit dem Status Healthy aufgeführt sein.

Produzieren für das Topic
Nachdem wir ein Topic mit Standardkonfiguration erstellt haben, können wir nun beginnen, Datensätze an dieses Topic zu senden. Führen Sie dazu den folgenden Befehl im Container aus und senden Sie Ihre Messages.
| |
Mit diesem Befehl werden 2 Messages an das Topic my-amazing-topic ohne Schlüssel und mit den Werten foo und bar, einige Zeichenketten, erstellt.
Man kann sehen, dass die Messages für das Topic erstellt wurden und im Topic verbleiben, indem man zur Registerkarte Topics navigiert.
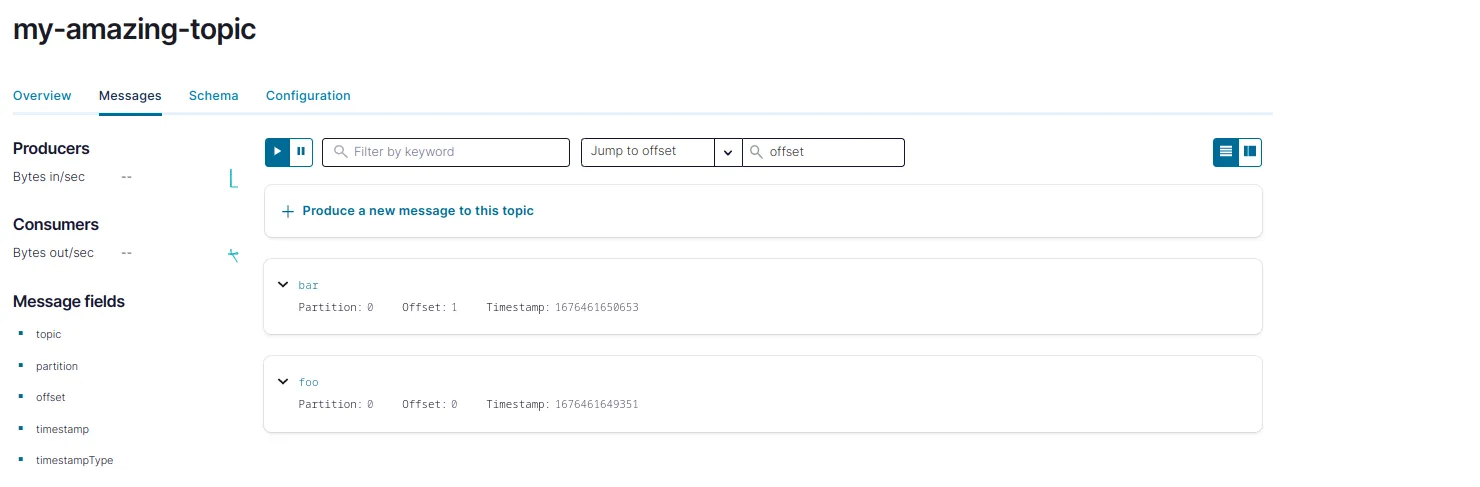
Wenn Sie auf die Registerkarte Schema klicken, werden Sie feststellen, dass kein Schema vorhanden ist. Das bedeutet, dass das Topic Datensätze mit unterschiedlichen Schemata enthalten kann, z. B. Strings oder Json-Strings. Es wird kein Schema erzwungen, was in der Produktion natürlich keine gute Praxis ist; daher die Notwendigkeit des Containers schema-registry. Aber machen Sie sich jetzt keine Sorgen, wir werden diesen Punkt in unserem nächsten Blog-Beitrag ansprechen, in dem wir eine kleine Producer-Anwendung bauen werden, die Avro-Datensätze mit Schema-Validierung an Kafka sendet.
Verbrauchen aus dem Topic
Der letzte Schritt besteht darin, die soeben erstellten Messages aus dem Topic zu konsumieren. Geben Sie dazu im Container den folgenden Befehl ein
| |
Den Cluster beenden
Wenn Sie genug mit Ihrem Kafka-Cluster gespielt haben, möchten Sie ihn vielleicht abschalten. Um dies zu tun, cd in dieses Projekt-Repos wieder und docker-compose die Infrastruktur nach unten.
| |
Was kommt als nächstes?
In einem nächsten Blog-Beitrag werden wir sehen, wie man - ausgehend von dieser Vanilla-Kafka-Infrastruktur - Avro-Datensätze für Kafka erzeugt. Bleiben Sie dran!
📝 Gefällt dir, was du liest?
Dann lass uns in Kontakt treten! Unser Engineering-Team wird sich so schnell wie möglich bei dir melden.