Technologie
Kafka 101 Tutorial - Real-Time-Dashboarding mit Druid und Superset

10. Mai 2023

💡 Einführung
In diesem neuen Blogbeitrag (oder GitHub-Repository) bauen wir auf allem auf, was wir bisher in dieser Kafka 101 Tutorial-Serie gesehen haben, nämlich:
und wir werden sehen, wie wir unsere Streaming-Daten in eine echtzeitfähige Datenbank, Apache Druid, einfließen lassen können! Darüber hinaus werden wir sehen, wie wir die Daten, die wir erzeugen (entweder aus unserem Rohdatenstrom oder unserem Flink-aggregierten Strom), mithilfe von echtzeitfähigen Dashboards, die von Apache Superset unterstützt werden, visualisieren können. Beachten Sie, dass wir bisher nur Apache-Technologien verwenden. Das liegt daran, dass wir uns für die Open-Source-Community 🤗 engagieren.
Die beiden neuen Dienste, die wir in diesem Artikel vorstellen, sind etwas weniger bekannt als das, was wir bisher verwendet haben, daher werde ich sie nur kurz vorstellen.
🧙♂️ Apache Druid
- Druid ist ein spaltenorientierter Datenspeicher, was bedeutet, dass Daten spaltenweise und nicht zeilenweise gespeichert werden. Dadurch ermöglicht es eine effiziente Komprimierung und schnellere Abfrageleistung.
- Druid ist auf OLAP (Online Analytical Processing) Abfragen optimiert, was bedeutet, dass es für komplexe Abfragen auf großen Datensätzen mit geringer Latenzzeit ausgelegt ist.
- Druid unterstützt sowohl die Stapelverarbeitung als auch die Echtzeit-Datenübernahme, sodass es sowohl historische als auch Streaming-Daten verarbeiten kann.
- Druid enthält eine SQL-ähnliche Abfragesprache namens Druid SQL, mit der Benutzer komplexe Abfragen gegen ihre Daten schreiben können.
- Druid integriert sich mit einer Vielzahl anderer Datenverarbeitungs- und Analysetools, darunter Apache Kafka, Apache Spark und Apache Superset.
♾ Apache Superset
Apache Superset ist eine moderne, Open-Source-Business-Intelligence-(BI)-Plattform, die es Benutzern ermöglicht, ihre Daten in Echtzeit zu visualisieren und zu erkunden.
- Superset wurde ursprünglich von Airbnb entwickelt und später als Open Source an die Apache Software Foundation gespendet.
- Superset ist darauf ausgelegt, eine Vielzahl von Datenquellen anzubinden, darunter Datenbanken, Data Warehouses und Big Data-Plattformen.
- Superset umfasst eine webbasierte GUI, mit der Benutzer Diagramme, Dashboards und Datenvisualisierungen mithilfe einer Drag-and-Drop-Oberfläche erstellen können.
- Superset bietet eine Vielzahl von Visualisierungsoptionen, darunter Balkendiagramme, Liniendiagramme, Scatterplots, Heatmaps und geografische Karten.
- Superset enthält eine Reihe von integrierten Funktionen für die Datenexploration und -analyse, darunter SQL-Editoren, Tools zur Datenprofilerstellung und interaktive Pivot-Tabellen.
🐳 Anforderungen
Um dieses Projekt zum Laufen zu bringen, benötigen Sie lediglich minimale Voraussetzungen: Sie müssen Docker und Docker Compose auf Ihrem Computer installiert haben.
Die Versionen, die ich für den Aufbau des Projekts verwendet habe, sind:
| |
Falls Ihre Versionen unterschiedlich sind, sollte das kein großes Problem darstellen. Es könnte jedoch vorkommen, dass einige der folgenden Schritte Warnungen oder Fehler verursachen, die Sie selbst beheben müssen.
🏭 Infrastruktur
Um alles zum Laufen zu bringen, müssen Sie den gesamten Producer-Teil (das Repository aus dem vorherigen Artikel) sowie Druid und Superset zum Laufen bringen. Gehen Sie dazu wie folgt vor:
| |
⚠ Es kann sein, dass Sie das Skript
start.sherst ausführbar machen müssen, bevor Sie es ausführen dürfen. Wenn dies der Fall ist, geben Sie einfach den folgenden Befehl ein:
| |
Der Druid docker-compose-Datei geht davon aus, dass der Kafka-Cluster im Docker-Netzwerk flink_sql_job_default läuft. Dies sollte der Fall sein, wenn Sie das Repository flink_sql_job geklont und die Infrastruktur mit den zuvor aufgeführten Befehlen gestartet haben. Andernfalls passen Sie einfach die Verweise auf das Docker-Netzwerk flink_sql_job_default in der docker-compose-Datei an.
Überprüfung der Funktionsfähigkeit
Um zu überprüfen, ob alle Dienste ausgeführt werden (Sie werden feststellen, dass jetzt viele Docker-Container ausgeführt werden), besuchen Sie die folgenden URLs und überprüfen Sie, ob alle Benutzeroberflächen ordnungsgemäß geladen werden:
- Kafka: http://localhost:9021
- Flink: http://localhost:18081
- Druid: Benutzername ist
druid_systemund das Passwort lautetpassword2http://localhost:8888 - Superset: Benutzername ist
adminund das Passwort lautetadminhttp://localhost:8088
Sie sollten etwas Ähnliches sehen wie:
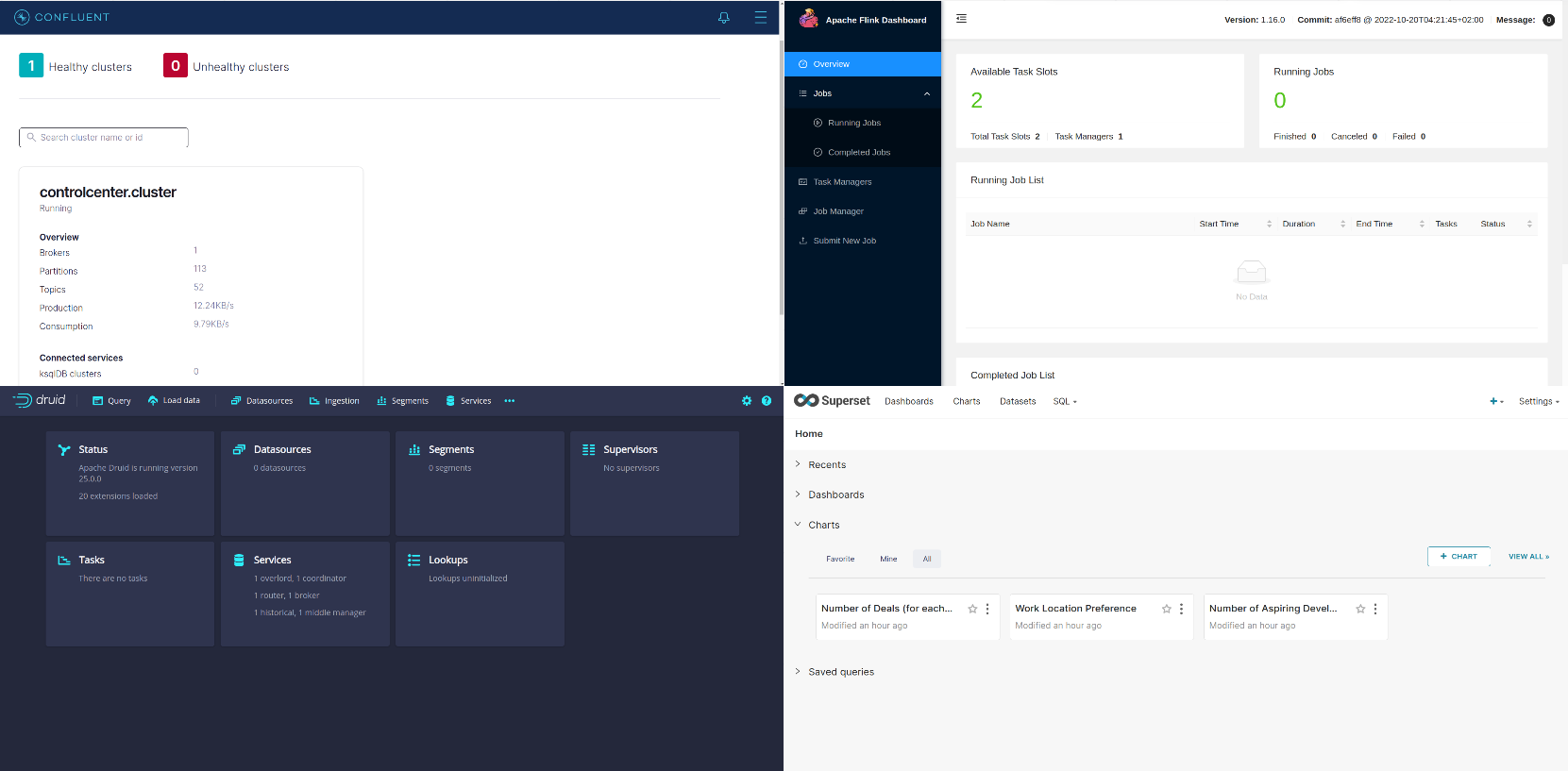
Die Beziehung zwischen allen Diensten wird mit dem folgenden Flussdiagramm veranschaulicht.
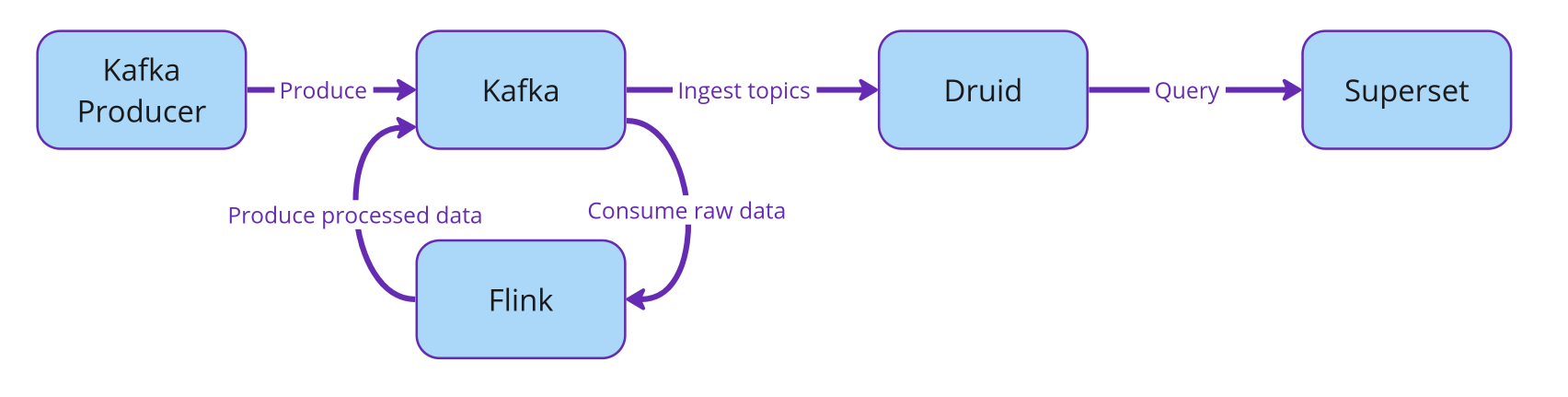
In den folgenden Abschnitten werden wir sehen, wie wir die Stream-Einbindung von Apache Druid aus unserem Kafka-Cluster einrichten und dann Druid mit Superset verknüpfen, um Echtzeit-Dashboards zu erstellen!
🌀 Druid Streaming-Datenübernahme
Der Kafka-Producer, den wir gestartet haben, erzeugt Nachrichten im Topic SALES. Dabei handelt es sich um künstlich erzeugte Verkaufsvorgänge, die jede Sekunde mit dem folgenden Schema erzeugt werden:
| |
Als Erstes werden wir Druid mit unserem Kafka-Cluster verbinden, um die Streaming-Einbindung dieses Topics zu ermöglichen und die Daten in unserer Echtzeitdatenbank zu speichern.
Wir werden dies über die Benutzeroberfläche von Druid unter http://localhost:8888 durchführen. Im Folgenden zeigen wir schrittweise, wie Sie die Streaming-Spezifikation erstellen können. Beachten Sie jedoch, dass die Spezifikation einfach über die REST-API von Druid als JSON gepostet werden kann.
Entwurf der Stream-Datenübernahmespezifikation
Der erste Schritt besteht darin, auf die Schaltfläche Load data zu klicken und die Option Streaming auszuwählen.
Wählen Sie dann Start a new streaming spec, um unsere benutzerdefinierte Streaming-Spezifikation zu erstellen.
Sobald dies erledigt ist, wählen Sie Apache Kafka als Quelle aus.
Schreiben Sie anschließend die Adresse des Kafka-Brokers und den Namen des Topics und klicken Sie auf “Konfiguration anwenden”. Auf der linken Seite sollten Sie dann Beispieldatenpunkte aus unserem Topic SALES sehen. Beachten Sie, dass die Daten nicht deserialisiert sind, da dies die Rohdaten sind, die von Kafka stammen. Wir müssen den Avro-Deserializer hinzufügen. Klicken Sie dazu auf die Schaltfläche Edit spec.
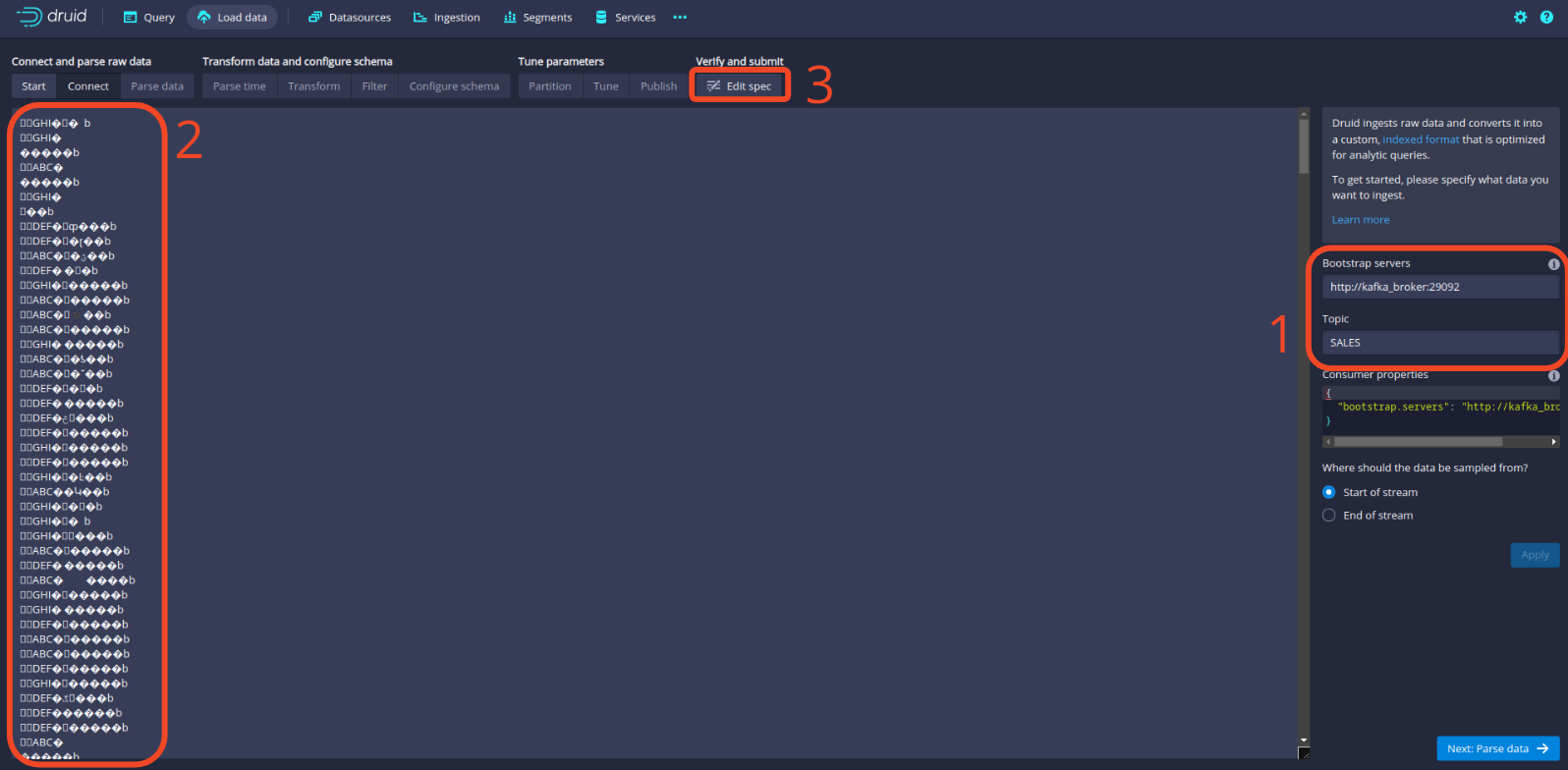
In der Spezifikationskonfiguration fügen Sie bitte Folgendes hinzu (danke Hellmar):
| |
Klicken Sie dann auf die Schaltfläche Parse data, um zur Bearbeitung der Spezifikation zurückzukehren.
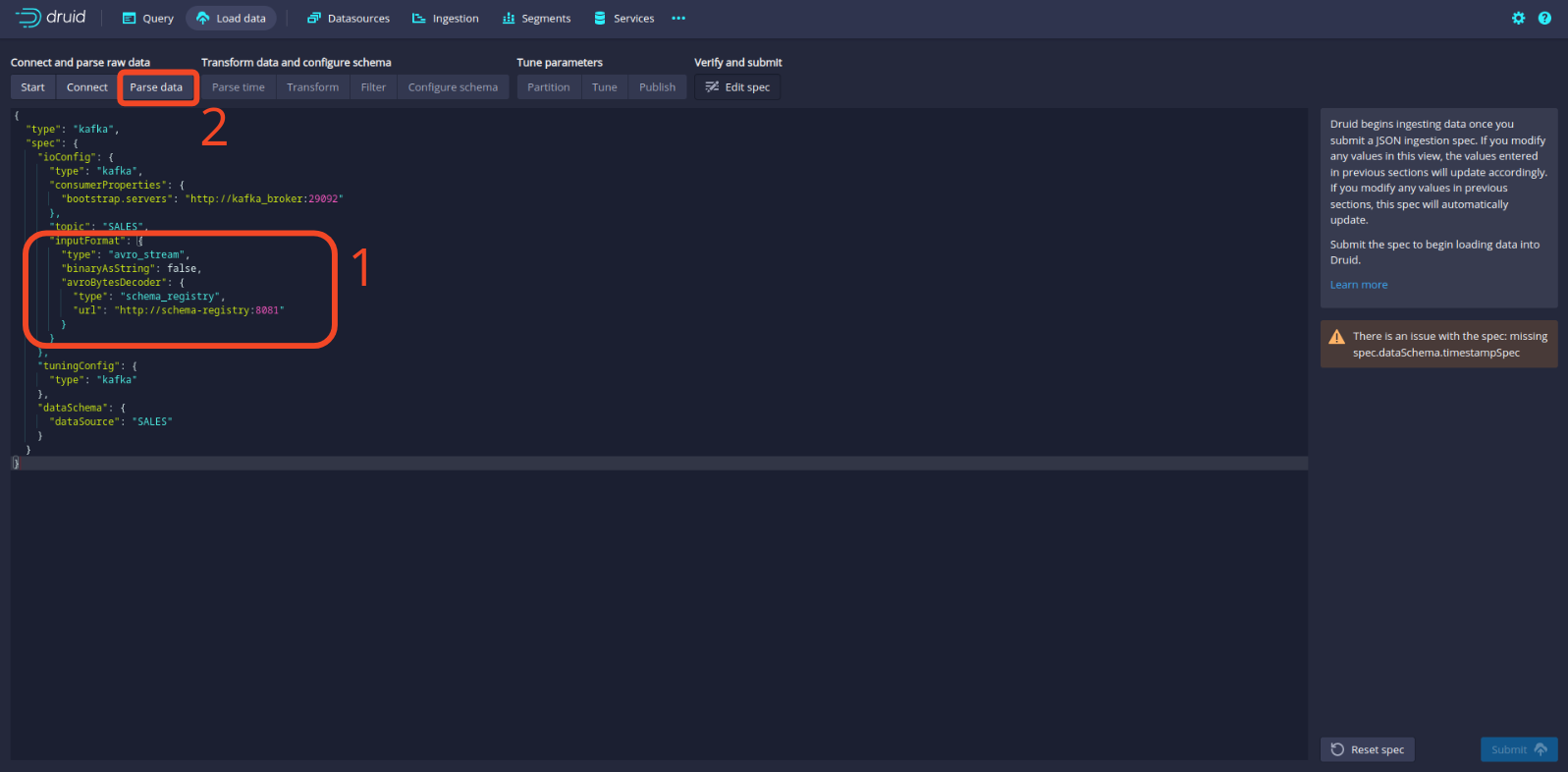
Jetzt sollten Sie sehen, dass unsere Daten ordnungsgemäß deserialisiert werden! Klicken Sie auf die Schaltfläche Parse time, um fortzufahren.
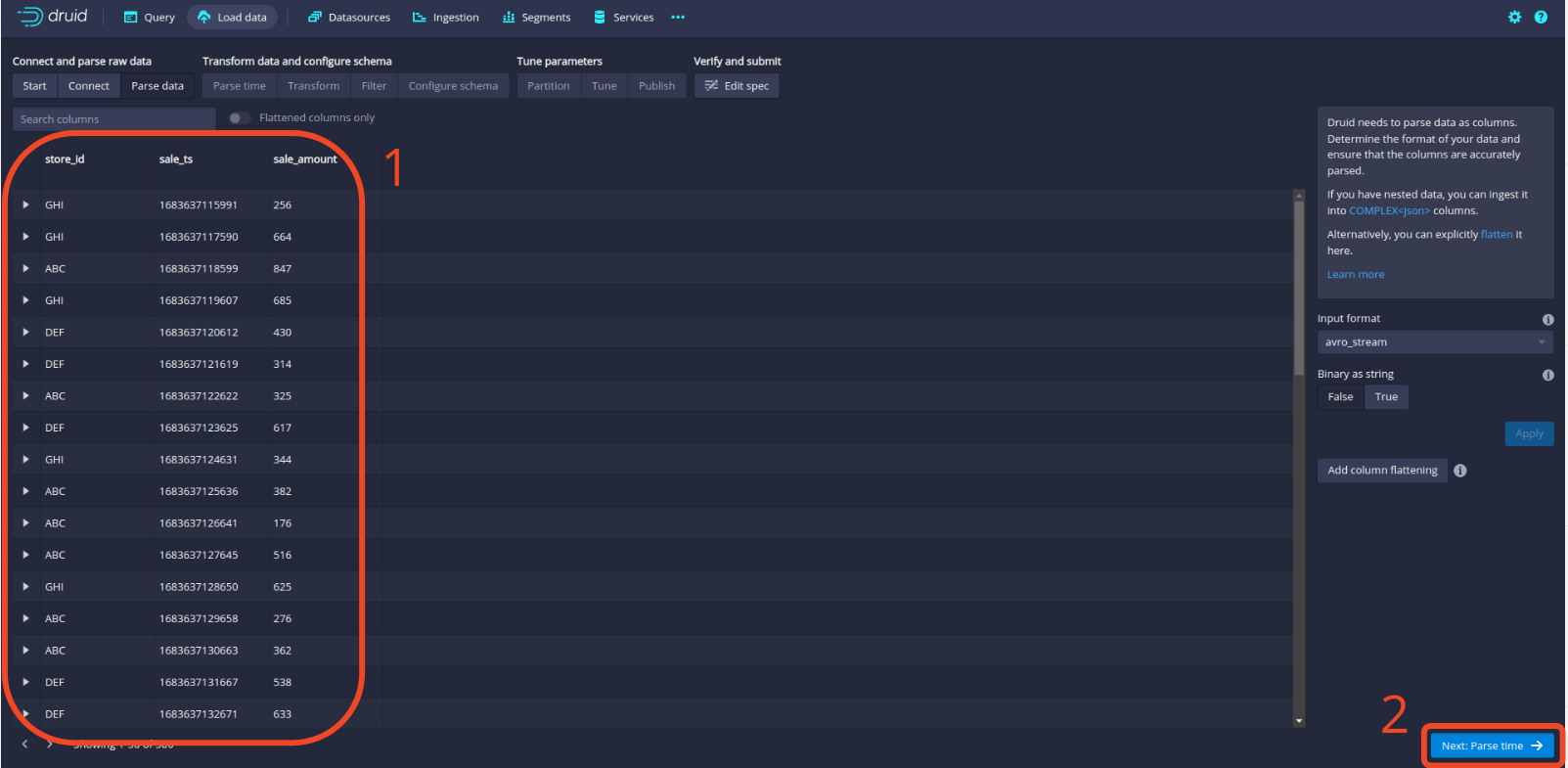
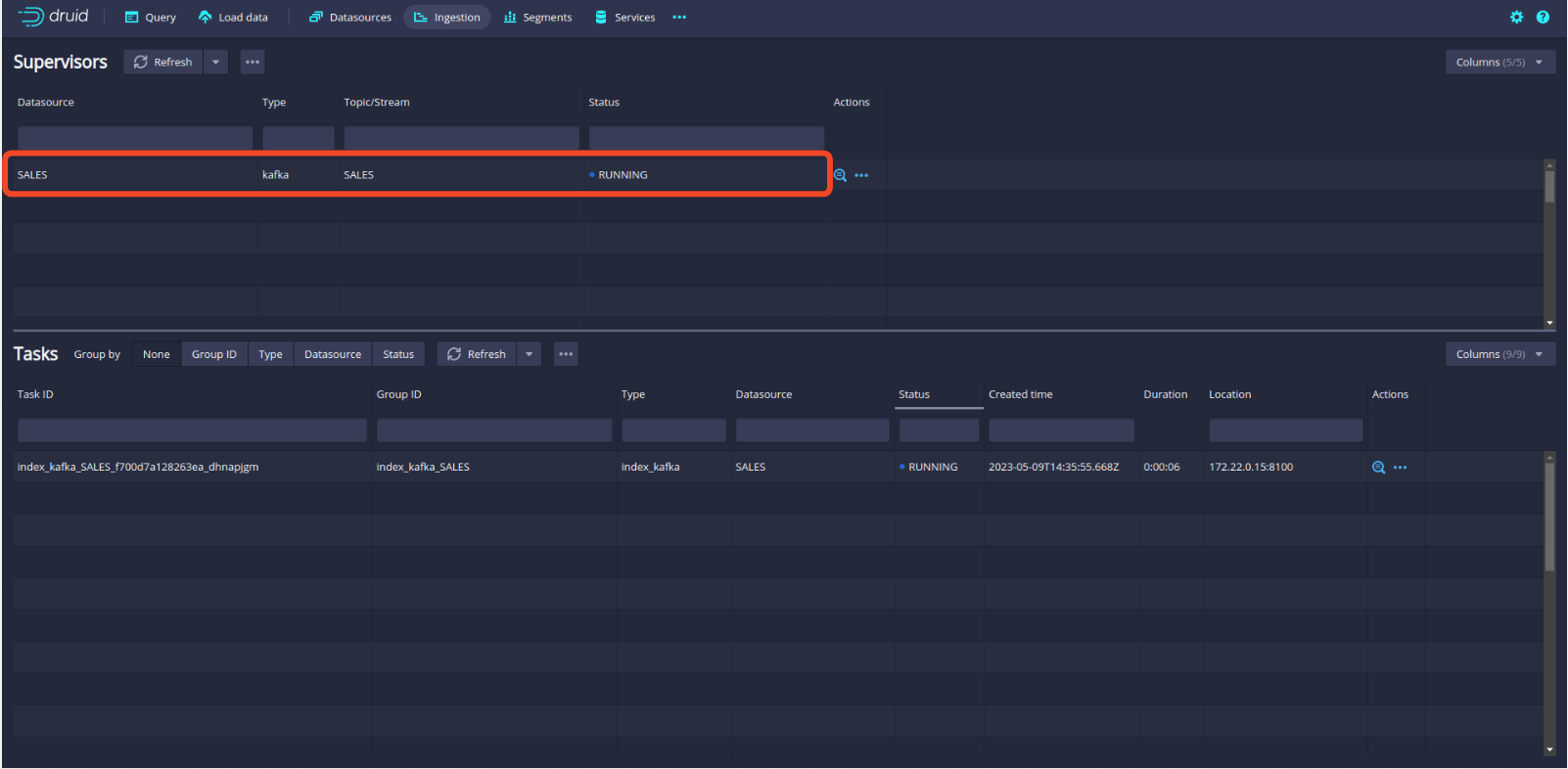
Von nun an gibt es nicht viel mehr zu bearbeiten. Klicken Sie einfach durch die Panels, bis die Streaming-Spezifikation übermittelt wird. Die Benutzeroberfläche von Druid leitet automatisch zur Registerkarte Ingestion weiter, auf der Sie Folgendes sehen sollten, was darauf hinweist, dass Druid erfolgreich von Kafka verarbeitet wird.
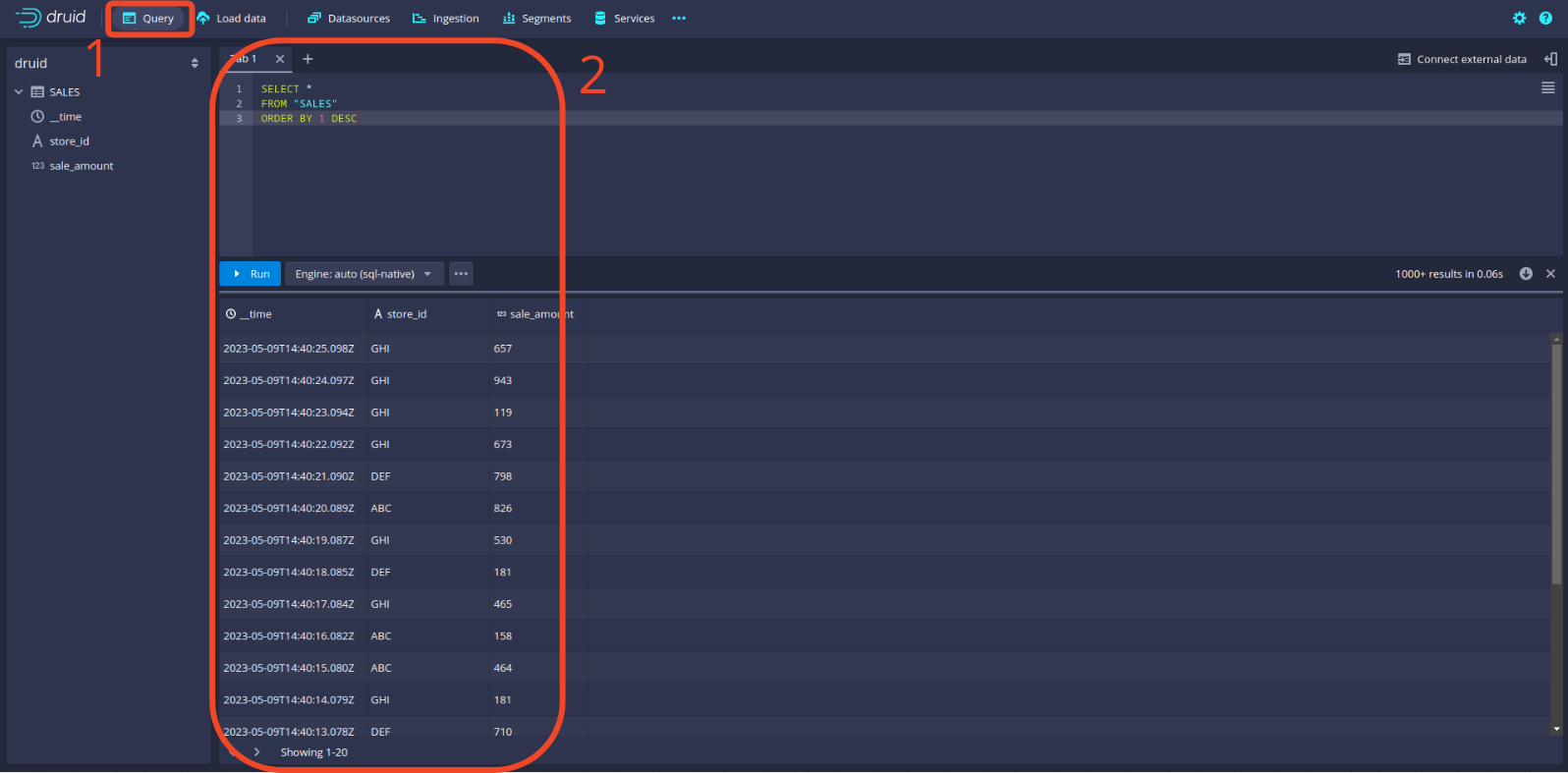
Schließlich können Sie überprüfen, ob die Daten ordnungsgemäß in Druid geladen wurden, indem Sie zur Registerkarte Query wechseln und eine Testabfrage durchführen. Hier sehen Sie ein Beispiel:
🎉 Die Stream-Einbindung ist eingerichtet und Druid wird nun weiterhin auf das Kafka-Topic SALES hören.
🖼 Datenvisualisierung in Superset
Nun, da die Daten erfolgreich in unsere Streaming-Datenbank eingefügt werden, ist es an der Zeit, unser Dashboard zu erstellen, um die Verkäufe dem Management zu berichten!
Navigieren Sie zur Superset-Benutzeroberfläche unter localhost:8088.
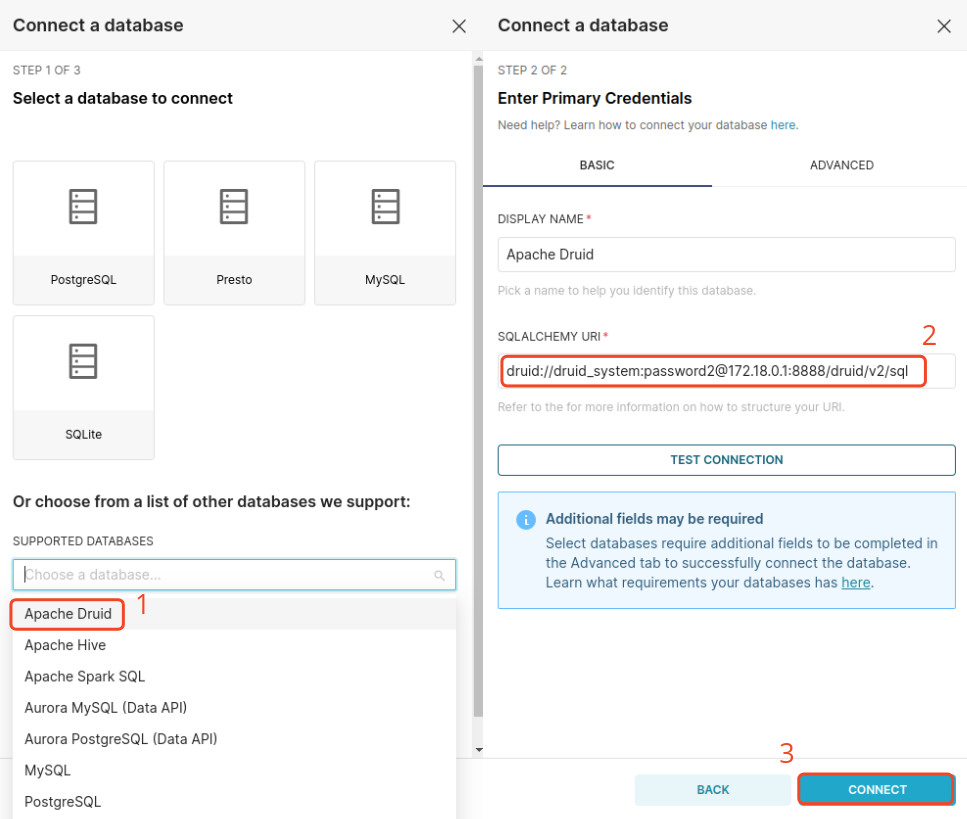
Das Erste, was wir tun müssen, ist, unsere Druid-Datenbank mit Superset zu verbinden. Klicken Sie dazu auf die Schaltfläche + in der oberen rechten Ecke und wählen Sie Data und Connect database. Folgen Sie dann den unten angezeigten Schritten. Beachten Sie, dass der Verbindungszeichenfolge Folgendes enthält:
- Datenbanktyp:
druid - Datenbankanmeldeinformationen:
druid_systemundpassword2 - Datenbank-SQL-Endpunkt:
172.18.0.1:8888/druid/v2/sql
Da Superset nicht im selben Docker-Netzwerk wie die anderen Dienste läuft, müssen wir darauf über den Host zugreifen. Dies hängt von Ihrem Betriebssystem ab. Siehe Superset-Dokumentation.
Im Wesentlichen gelten die folgenden Einstellungen:
host.docker.internalfür Mac- oder Ubuntu-Benutzer172.18.0.1für Linux-Benutzer
Dashboard erstellen
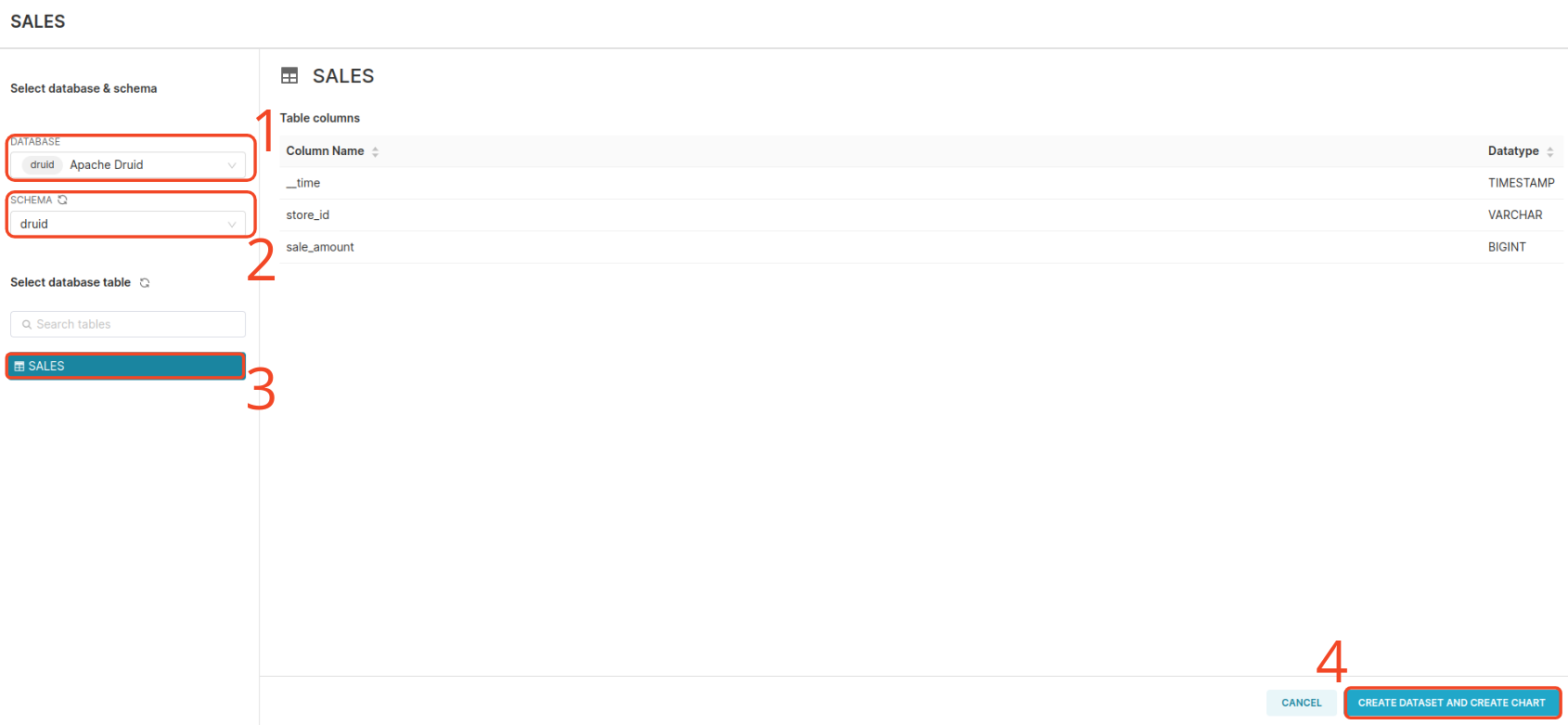
In Superset besteht ein Dashboard aus Charts. Daher ist der erste Schritt die Erstellung eines Charts. Um ein Chart zu erstellen, müssen wir ein Dataset-Objekt erstellen. Klicken Sie auf die Schaltfläche Dataset und folgen Sie den untenstehenden Schritten, um ein Dataset aus dem SALES-Topic zu erstellen.
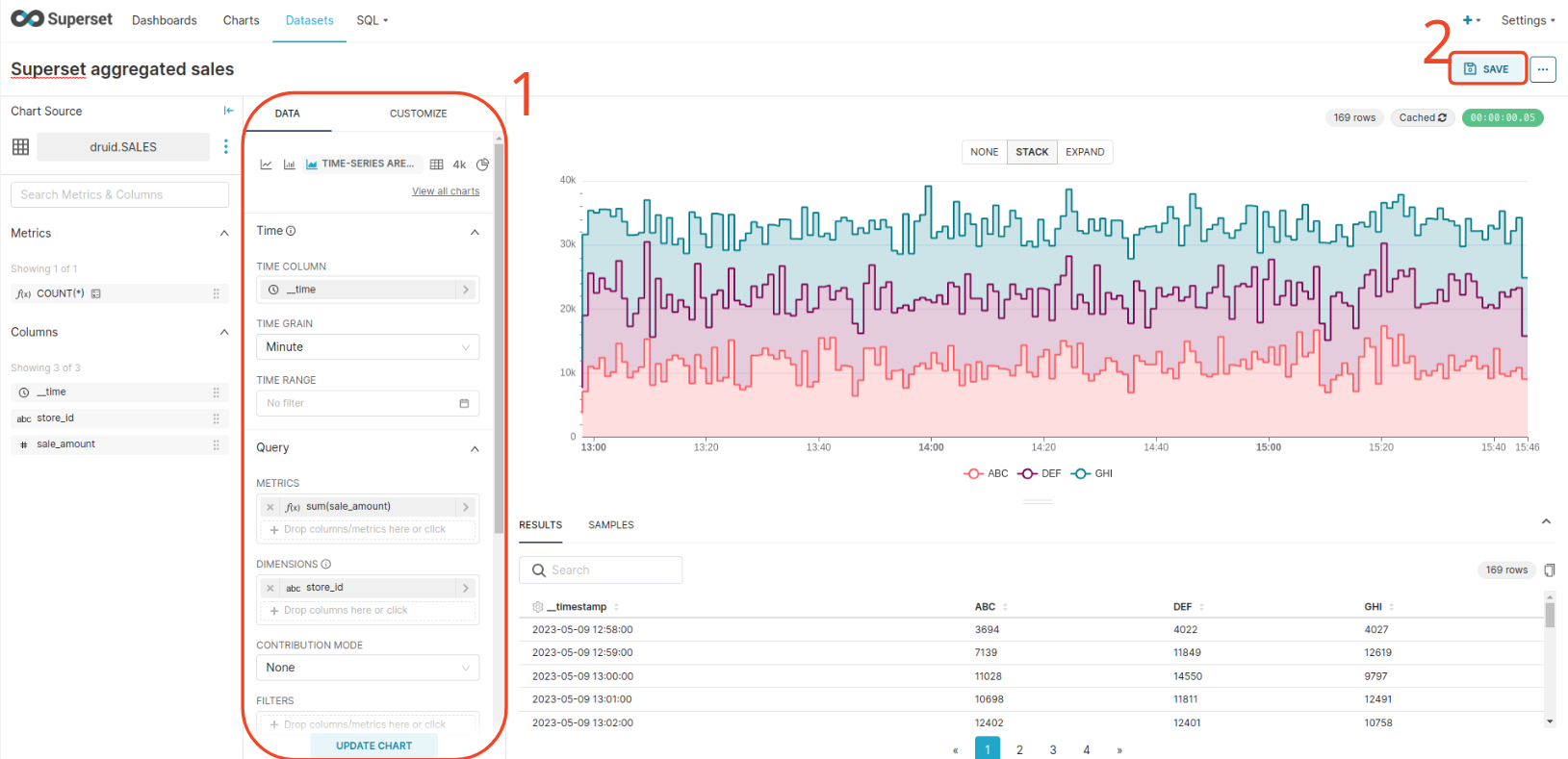
Create a time-series area chart from the SALES dataset and add a couple of configurations to the chart, as shown below. Then save the Chart and add it to a new Dashboard.
Erstellen Sie ein Zeitreihenflächendiagramm aus dem “SALES”-Dataset und fügen Sie dem Diagramm einige Konfigurationen hinzu, wie unten dargestellt. Speichern Sie dann das Chart und fügen Sie es einem neuen Dashboard hinzu.
🐿 Apache Flink hinzufügen
Sie werden feststellen, dass das von uns erstellte Superset-Chart die 1-Minuten-Aggregation durchführt, die auch unser Flink-Job durchführt. Lassen Sie uns nun direkt die aggregierten Daten von Apache Flink verarbeiten und sehen, ob beide Aggregationen die gleichen Zahlen anzeigen.
Die Schritte, die Sie befolgen sollten:
- Starten Sie den Flink-Job.
- Schreiben Sie die Streaming-Spezifikation vom neuen Topic in Druid.
- Erstellen Sie ein neues Chart in Superset und fügen Sie es dem Dashboard hinzu.
Flink-Job starten
Um den Flink-Aggregationsjob zu starten, der aggregierte Verkäufe pro Geschäft pro 1-Minuten-Fenster berechnet, geben Sie die folgenden Befehle ein:
| |
Sie werden feststellen, dass vom Flink-Job ein neues Topic namens SALES_AGGREGATE in Kafka erstellt wurde.
Wiederholen Sie nun die Vorgänge in Bezug auf Druid und Superset, um die Daten in Druid einzufügen und das Chart in Superset zu erstellen.
Siehe das folgende Dashboard:
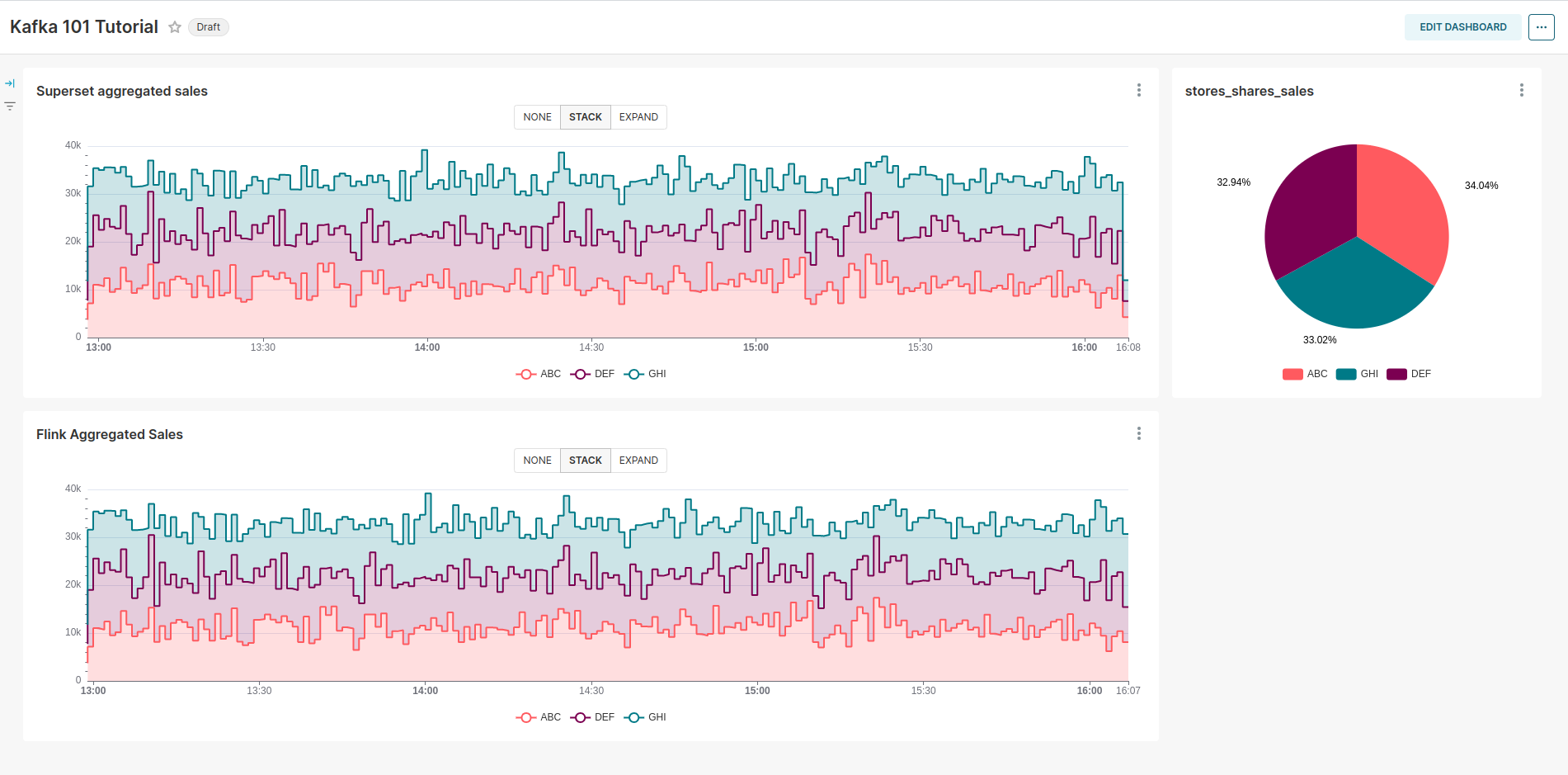
Wie erwartet sind die beiden Charts identisch, da dieselbe Aggregation durchgeführt wird. In einem Fall erfolgt die Aggregation in Superset, während sie im anderen Fall über Apache Flink durchgeführt wird und Superset die Daten lediglich aus der Datenbank liest, ohne selbst Arbeit zu leisten. Zusätzlich haben wir ein Diagramm erstellt, das den Anteil jedes Geschäfts am Gesamtumsatz zeigt. Wie erwartet ist dieser Anteil aufgrund der gleichmäßigen Verteilung der Verkäufe in jedem Geschäft annähernd gleich.
☠ Infrastruktur abbauen
Wenn Sie mit Superset fertig sind, befolgen Sie diese Schritte, um die gesamte Infrastruktur zu stoppen. Zuerst beenden wir Druid und Superset und dann Flink, Kafka und den Avro-Records-Producer. Die Befehle sind unten aufgeführt.
| |
Stellen Sie sicher, dass das Skript stop.sh im Ordner real_time_dashboarding ausführbar ist.
📌 Fazit
In diesem Blogbeitrag haben wir die gesamte Datenpipeline von Anfang bis Ende behandelt. Wir haben mit dem Kafka-Producer begonnen, der qualitativ hochwertige Datensätze mit Avro-Schema und dem Schema-Register erstellt und sie an Kafka sendet. Anschließend haben wir die Streaming-Analytics-Pipeline mit dem Flink-Cluster behandelt, der zeitliche Aggregationen auf den Rohdaten durchführt und sie zurück zu Kafka schickt. Wir haben auch gezeigt, wie man mit Apache Druid als Echtzeit-OLAP-Datenbank startet, um Daten aus Kafka zu speichern und schnelle Abfragen zu ermöglichen. Zuletzt haben wir gesehen, wie man unsere Streaming-Datenbank mit Superset verbindet, um aussagekräftige Visualisierungen und Dashboards zu erstellen. Superset fungiert hier als unser Business-Intelligence-Tool.
📝 Gefällt dir, was du liest?
Dann lass uns in Kontakt treten! Unser Engineering-Team wird sich so schnell wie möglich bei dir melden.