Technology
Kafka 101 Tutorial - Kafka Sales Producer with Apache Avro

March 30, 2023

Requirements
The project was developed using openjdk 11.0.18 and built with Apache Maven 3.8.7.
To check your version of Java and Maven, type the following commands; with the output for my configuration below.
| |
If you do not have these configs, or if you do not have/do not want to install Java and Maven; I also built a Docker image for this small Java application. Make sure to have Docker installed. My Docker config is
| |
The application’s image can be pulled from my dockerhub repo.
Build the Project
Clone the Repository
The first step is to clone this repository. cd into the folder where you want to host this project’s repo and type the command
| |
If you want to play around with the Kafka producer, you can do so and build the application’s jar-file using the following command within the ./kafka_sales_producer folder.
| |
You can also use the provided Dockerfile to build your own Docker image running your producer. To build your local image, run the following command from within the ./kafka_sales_producer folder.
| |
The Infrastructure
This repo only contains the Java application that publishes messages to an existing Kafka cluster. This means that this code won’t run except it can pusblish messages to an existing Kafka cluster. In order to get this application to run, we need to start a Kafka cluster and related services…
The good thing is that this was the subject of my previous blog post! To get a running local Kafka infrastructure is easy: simply refer to my github repo that accompanies the blog post.
To get the cluster up and running do the following
| |
You should see 4 services running on the Docker network kafka_101_default:
- control-center
- schema-registry
- broker
- zookeeper
Now that the infrastructure is running, we can start the Kafka producer!
Run the Application
One can run the application directly in the CLI using the java command, or in a Docker container (which I recommend as a good practice).
In the CLI
You can run the producer locally using the java CLI. The App.java main method takes some command line arguments for the adress of the Kafka server, and of the schema registry. Because yes, in this repo we are also going to play around with Confluent’s schema registry. For a video intro about the schema registry, and why you should use the schema registry in th first place; refer to this video.
Assuming you started the Kafka cluster using the proposed method, the Kafka broker should be running on localhost:9092, and the schema registry on localhost:8081. If you picked a different port mapping, update the value for ports and type the command below to start producing events:
| |
In a Docker Container
Alternatively, you can also run the application inside a Docker container. If you run the producer in a Docker container, the Kafka and schema registry services are not local to the producer anymore. So you have to connect the producer to the network where those containers are running, and address them using their containers names. Again, if you followed the proposed approach to get the infra running, the Kafka broker will be running on http://broker:29092, and the schema registry on http://schema-registry:8081; and all these containers should be running on the kafka_101_default network.
To check that this is indeed the case, check that the network does exist:
| |
To check that the broker and the schema registry are indeed connected to this network, type
| |
Get the producer producing, by running the command
| |
Sanity Checks
By default, the producer should be producing messages in the auto-created SALES topic at a frequency of 1 msg/s. To check that messages are indeed being produced; go to the Confluent control center UI on localhost:9021 and navigate to the Topics tab. Click on the SALES topic and then on the Messages tab. You should see messages reaching the cluster there.
You should see something like the below:
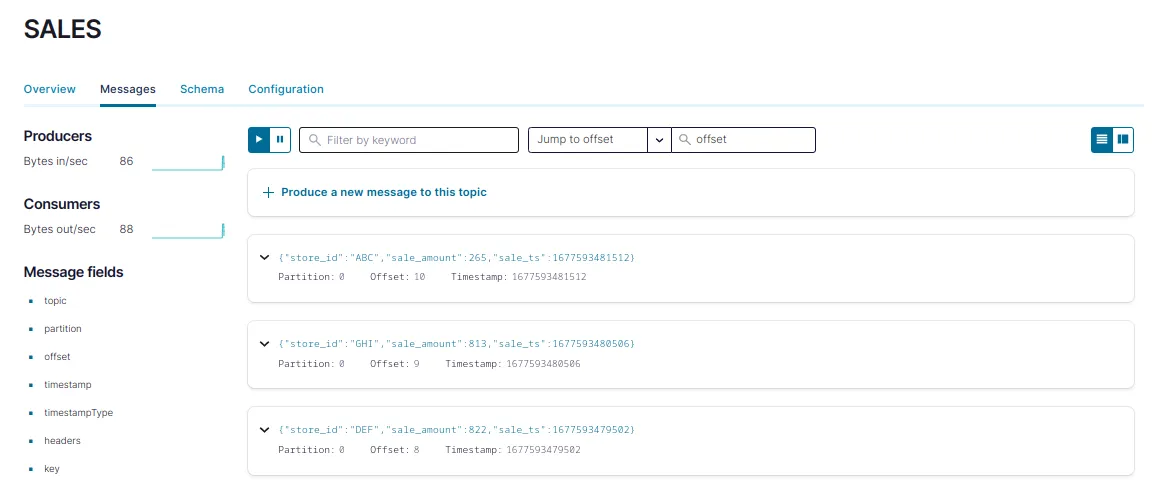
One Step Further
To go one step further, we will leverage the schema registry to enforce schema validation. When running the Java application, as the SALES topic was originally not registered, it was auto-created when publishing to it. And by default at topic creation, schema validation is not enabled; even though the producer did register the schema in the schema registry.
To see that the schema was indeed registered, navigate to the Schema tab of the SALES topic in the UI. Or type the following in your browser:
| |
But the fact that schema validation is not enabled means that the producer application could start producing “contaminated” messages not fitting the schema, and get away with it. To try that out, we will manually add some messages to the topic using Confluent CLI, simply sending strings without keys.
| |
Then consume those messages from the CLI.
| |
You will see something like below

And because messages are serialized using Avro, they display as weird characters in the terminal. But you see that the two messages hello and world were added to the topic. This is not a good behavior as this data does not fit the schema and might disrupt consumption on consumers side.
To circumvent this, let us enforce schema validation. This is done at the topic level, at topic creation. Let us delete the SALES topic and recreate it using:
| |
As you can see, sending messages that do not fit the schema will throw org.apache.kafka.common.InvalidRecordException. This ensures that contaminated records will not propagate to the consumers, and ultimately to the downstream applications.
You can start producing normally again using the producer which will send messages fitting the schema! Et voilà!
What is Coming Next?
This repo will be published as a blog post on Acosom website. In the following post (and repo), we will be using the introduced infra and concepts to get started with Apache Flink. We will use this fictitious sales data producer to create a streaming analytics pipeline with Flink using the multiple APIs. Now the cool things start !
📝 Like what you read?
Then let’s get in touch! Our engineering team will get back to you as soon as possible.